
Python3 教程-4. 编码与标识符
一、编码
1. 基础
编码描述的是二进制与文字之间的对应关系
计算机存储的文件在底层都是0101的形式存在于计算机之中的
| 编码 | ||
|---|---|---|
| ASCII | 英文字母,数字,特殊字符 | 最左边是0,预留位 ,8位一个字节,8bit=1byte,A是65,a是97 |
| gbk | 英文字母,数字,特殊字符和中文 | 一个字母:1byte,一个中文:2byte ,国标 |
| Unicode | 万国码 | 世界所有国家文字与二进制的对应关系,一个字符两个字节表示,后来4个字节,浪费空间,浪费资源 |
| UTF-8 | 对万国码的升级 | 最少用8位(1字节),1字节表示一个字符,一个中文3字节 |
编码不同,占用的字节就不同,不同编码之间不能相互识别,编码与解码必须一样
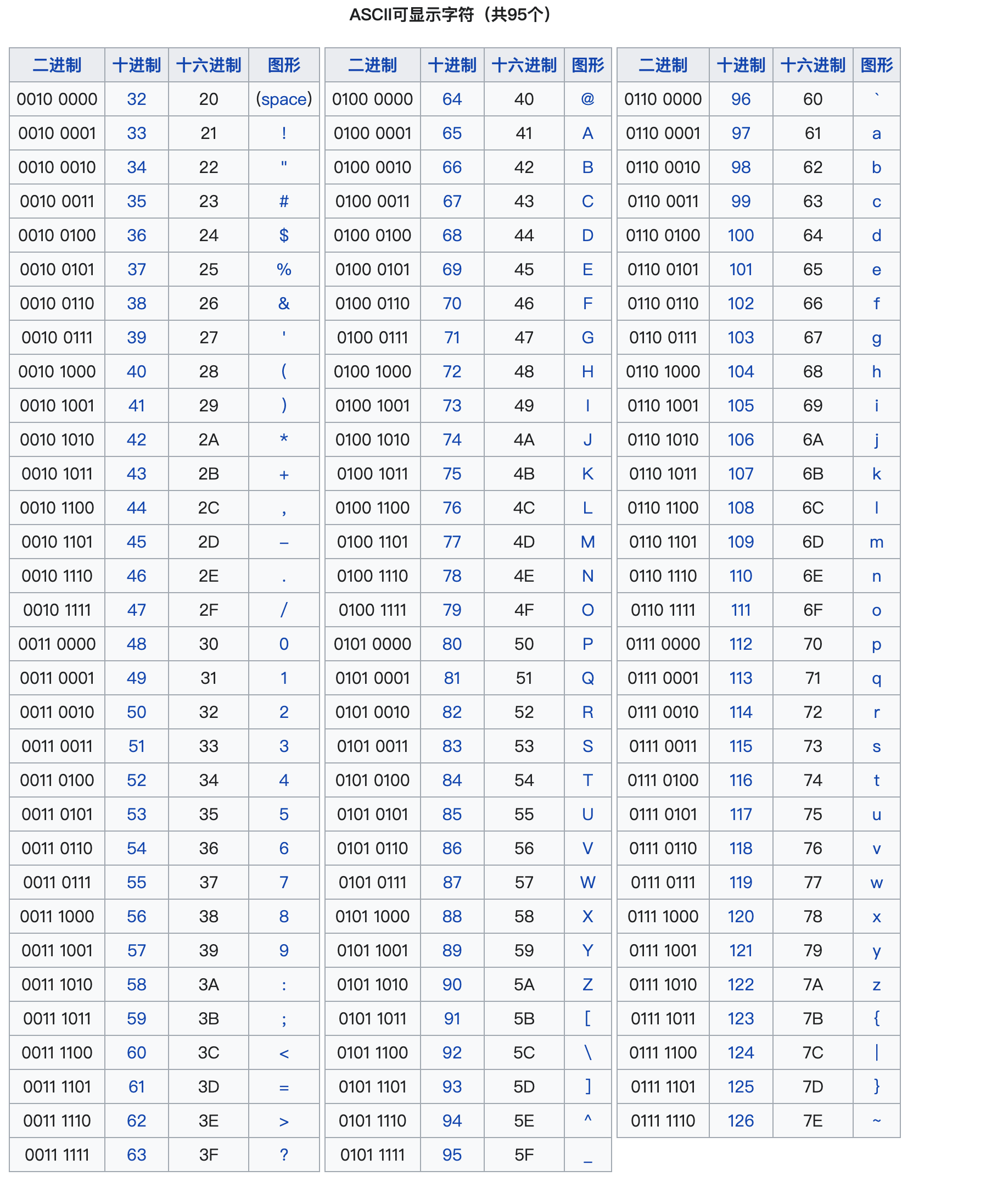
可显示字符编号范围是
32-126(0x20-0x7E),共95个字符。
2. 在内存中
- 在计算机内存中,统一使用 Unicode 编码,当需要将数据保存到硬盘或者需要网络传输的时候,就转换为非 Unicode 编码比如:UTF-8编码
- 数据在内存中全部是 Unicode 编码,不只是 python 语言,其他语言 java 等也是这么规定的,但是当你的数据用于网络传输或者存储到硬盘中,必须是非 Unicode 编码
- 不同编码之间,不能直接互相识别
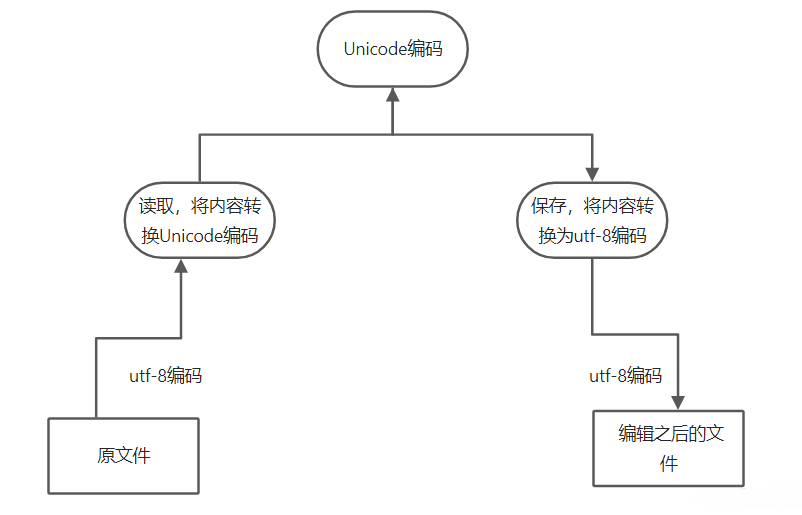
说明:文件的编码格式使 utf-8 编码,在编辑的时候,将你的数据字符串转换为 Unicode 字符读到内存中,进行编辑,编辑完毕之后,保存的时候再把 Unicode 转换的你的编码格式 utf-8 ,然后保存到文件
3. 编码如何转换📚
- bytes 数据类型非常特殊,唯一在内存中不是 Unicode 编码,它也不是不是字节
- bytes 类型也称作字节文本,他的主要用途就是网络的数据传输,与数据存储
3.1 bytes 类型表现形式
1 | 字符串表现形式 |
3.2 转化 str-bytes
- str-bytes:编码与解码
- 其它类型不能直接转化 bytes 类型,需要先转换成 str 字符串类型然后在进行转换
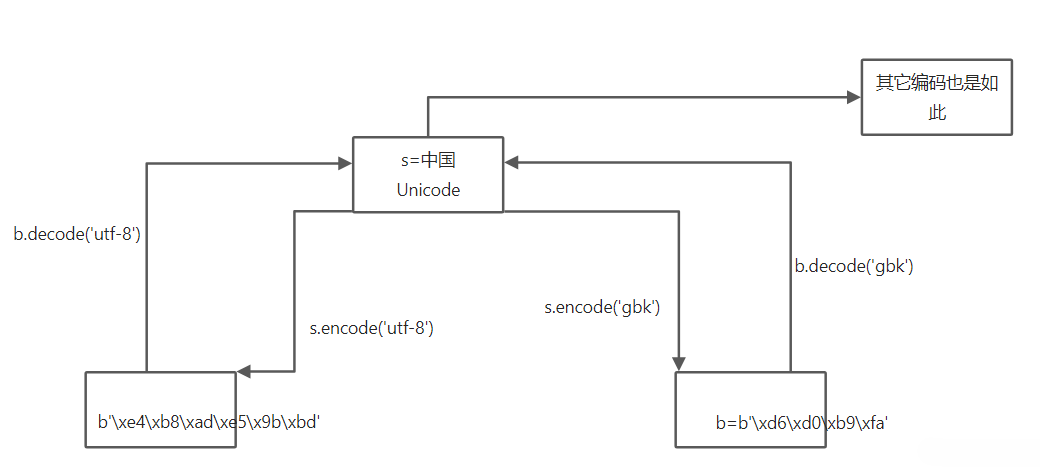
1 | s='中国' |
3.3 gbk 与 utf-8 转换
- 先在内存中转换成为我 Unicode 编码,然进行转换
3.4 utf-8 转换 gbk
- 将 utf-8 编码的中国转换为 gbk 编码
1 | s='中国' |
3.5 gbk 转换 utf-8
- gbk 编码转换为 utf-8 编码
1 | s='中国' |
3.6 基础换算
- 8 bit(比特)= 1 Byte(字节)
- 1024 Byte = 1 KB
- 1024 KB = 1 MB
- 1024 MB = 1 GB
- 1024 GB = 1 TB
- 1024 TB = 1 PB
- 1024 PB = 1 EB
- 1024 EB = 1 ZB
- 1024 ZB = 1 YB
- 1024 YB = 1 NB
- 1024 NB = 1 DB
快速记忆口诀:
小到大,乘 1024;大到小,除以 1024
比特换字节,直接除以 8
二、标识符
1. 注释规范
1.2 注释
注释是对代码的解释和说明,不会被 Python 解释器执行。在 Python 中,注释有两种类型:单行注释和多行注释。
1.3 单行注释
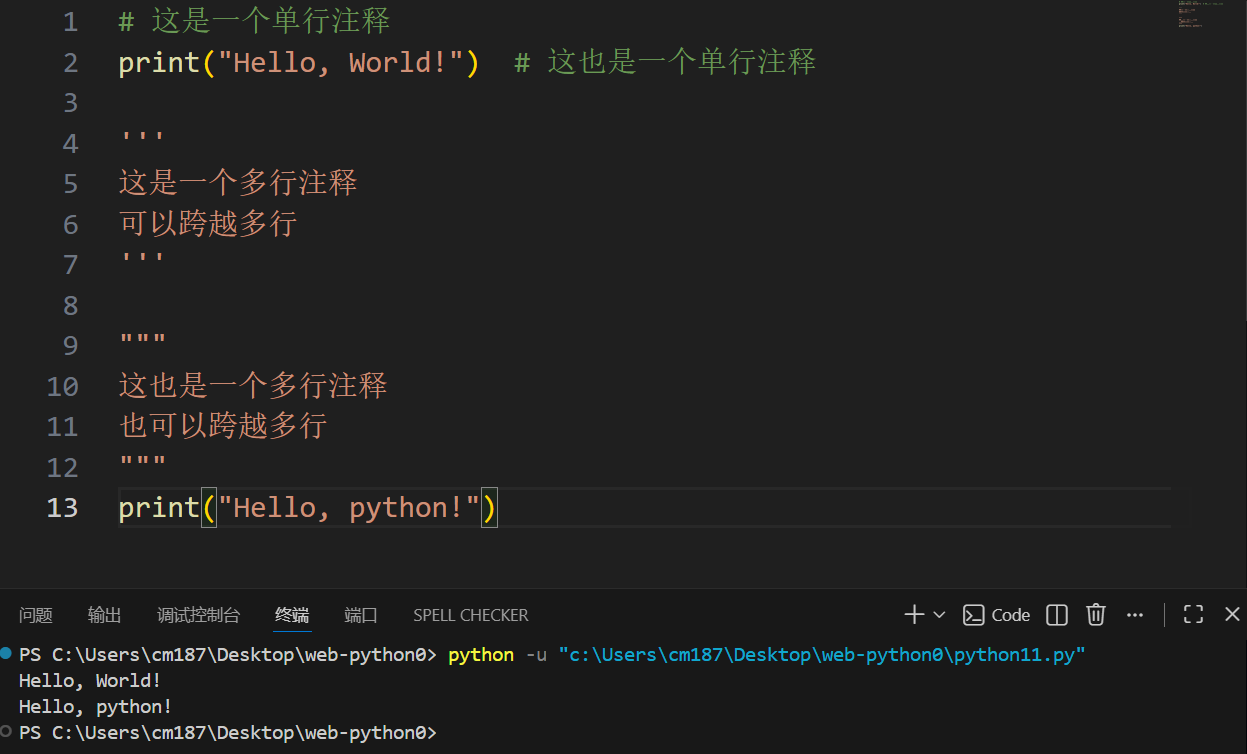
- 以
#开头,直到行尾的所有内容都被视为注释。
1 | # 这是一个单行注释 |
1.4 多行注释
- 可以使用三个单引号
'''或三个双引号"""括起来。
1 | ''' |
1.5 文档字符串📚
单行文档字符串与多行文档字符串的规范对比
- 单行文档字符串规范
单行文档字符串适用于功能简单、逻辑清晰的小型函数或类,其核心规范包括:
格式要求:使用一对双引号包裹,首尾引号与内容在同一行
内容规范:一句话完整说明功能,结尾带句号
适用场景:简单工具函数、无参数/返回值的类、功能单一的方法
优势:简洁明了,不增加代码行数,降低维护成本
==示例:==
1 | def is_even(num): |
- 多行文档字符串规范
多行文档字符串适用于功能复杂、有入参/返回值/异常的函数或类,是实际开发中最常用的写法:
格式要求:使用三重双引号包裹,结束的三引号单独占一行
内容结构:
首行:核心功能摘要(一句话)
空一行
详细说明:功能的详细描述、使用场景、注意事项
分段说明:参数、返回值、异常、示例等
适用场景:核心业务逻辑函数、公共API、复杂算法实现
优势:信息全面,结构清晰,便于自动生成专业文档
==示例:==
1 | def calc_circle_area(r): |
==扩展:主流文档字符串格式规范详解==
| 格式风格 | 核心特点 | 适用场景 | 工具支持 |
|---|---|---|---|
| Google 风格 | 简洁易读,学习成本低,结构清晰 | 通用项目、团队协作、中小型项目 | Sphinx (需napoleon扩展)、pdoc (原生支持)、主流 IDE |
| reStructuredText 风格 | 结构化强,语法复杂但精确,原生支持 Sphinx | 大型企业级项目、需要与 Python 官方文档统一的项目 | Sphinx(原生支持)、pdoc(部分支持) |
| NumPy/SciPy 风格 | 分栏式参数说明,格式严谨,适合数学公式 | 科学计算库、学术研究项目、数据处理工具 | Sphinx(需 numpydoc 扩展)、pdoc(原生支持) |
| Google 风格示例: |
1 | def add(a, b): |
reStructuredText风格示例:
1 | def add(a, b): |
NumPy/SciPy风格
1 | def multiply(a, b): |
工具链配置
根据选择的文档字符串风格,配置相应的工具
1.1 Sphinx配置
Google风格配置:
1 | # conf.py |
reStructuredText风格配置:
1 | # conf.py |
NumPy/SciPy风格配置:
1 | # conf.py |
1.2 pdoc配置
pdoc是一个轻量级的文档生成工具,配置简单:
1 | # 使用pdoc生成文档 |
文档字符串的编写原则
无论采用何种格式,高质量文档字符串应遵循以下原则:
- 准确性:严格描述函数/类的实际行为,避免误导
- 一致性:同一项目内保持统一的格式和风格
- 简洁性:避免冗长,只提供必要信息
- 实用性:包含使用示例、常见错误和注意事项
- 可维护性:随着代码变化及时更新文档字符串
项目规模与文档字符串风格选择指南
| 项目类型 | 推荐风格 | 主要理由 | 工具支持 |
|---|---|---|---|
| 小型/个人项目 | Google 风格 | 简洁易学,维护成本低 | 支持 Sphinx(pdoc)、pdoc、IDE 智能提示 |
| 中型企业项目 | Google 风格 | 团队协作友好,学习曲线平缓 | 支持主流工具,文档生成简单 |
| 大型框架/库 | reStructuredText | 与官方文档风格统一,支持复杂标记 | 与 Sphinx 无缝集成,适合生成完整用户手册 |
| 科学计算/数据分析项目 | NumPy/SciPy 风格 | 适合数学公式和参数约束描述 | 与科学计算工具链兼容,支持复杂公式展示 |
| 文档字符串不仅是给他人看的,更是给未来的自己看的。良好的文档字符串习惯将使代码库更具可持续性,为项目的长期成功奠定基础 |
2. 命名规则
- 第一个字符必须以
字母(a-z, A-Z)或下划线 _。 - 标识符的其他的部分由
字母、数字和下划线组成。 - 标识符对
大小写敏感,count 和 Count 是不同的标识符。 - 标识符对
长度无硬性限制,但建议保持简洁(一般不超过 20 个字符)。 禁止使用保留关键字,如 if、for、class 等不能作为标识符。
2.1 合法的标识符
示例:
1 | age = 25 # 普通变量名,最常见 |
2.2 不合法的标识符
示例:
1 | 2nd_place = "silver" # 错误:以数字开头 |
Python 3 允许使用 Unicode 字符作为标识符,可以用中文作为变量名,非 ASCII 标识符也是允许的
1 | 姓名 = "张三" # 合法 |
Python 可以同一行显示多条语句,方法是用分号 ; 分开。
2.3 下划线开头的标识符📚
以下划线开头的标识符是有特殊意义的:
- 单下划线开头
_foo代表不能直接访问的类属性,需通过类提供的接口进行访问,不能用 from xxx import * 而导入。 - 双下划线开头
__foo代表类的私有成员,以双下划线开头和结尾的__foo__代表 Python 里特殊方法专用的标识,例如__init__()代表类的构造函数。 - 小驼峰式命名法:第一个单词以小写字母开始,第二个单词的首字母大写 (如:yongQiang)。
- 大驼峰式命名法:每一个单字的首字母都采用大写字母 (如:FirstName、LastName)。
三、代码可读性优化
- 空格、缩进、空行使用
代码可读性是Python项目质量的核心指标之一,它直接影响代码的维护成本和团队协作效率。在Python开发中,空格、缩进和空行这三种看似微小的格式元素,实则是塑造代码结构的关键工具。本文将深入解析Python官方PEP8规范中的相关要求,通过丰富的代码示例,系统展示这三种元素的最佳实践场景和具体应用方法。
1. 空格使用规则
空格在Python中扮演着”语法辅助元素”的角色,通过精确控制空格位置,可以显著提升代码的可读性和一致性。
1.1 运算符周围的空格
PEP8明确规定,二元运算符(如+, -, *, /, ==, <, >, !=, and, or等)两侧应各添加一个空格:
1 | # 正确写法 |
例外情况:当运算符用于类型注解或装饰器参数时,不需要空格:
1 | # 类型注解不需要空格 |
1.2 逗号、分号、冒号的空格使用
逗号、分号和冒号作为分隔符,其空格使用有严格规范:
1 | # 正确写法:逗号后加空格,分号前不加空格 |
在函数参数列表中,逗号后应加空格,但等号两侧不应加空格:
1 | # 正确写法 |
1.3 多行表达式中的空格
对于长表达式,PEP8推荐使用括号进行隐式换行,而非反斜杠。多行表达式有两种主流的缩进方式:
1.3.1 垂直对齐式
所有行对齐到左括号所在列:
1 | # 垂直对齐式(适用于简单表达式) |
1.3.2 悬挂缩进式
缩进额外增加4个空格,形成视觉上的”悬挂”效果:
1 | # 悬挂缩进式(适用于复杂表达式) |
选择建议:在简单表达式中优先使用垂直对齐式,复杂表达式中使用悬挂缩进式。无论选择哪种方式,同一项目内应保持一致的多行表达式缩进风格。
同一项目内应保持一致的多行表达式缩进风格。
2. 类型注解的空格规范
Python 3.5+引入的类型注解有其特定的空格使用规则:
1 | # 正确写法 |
3. 链式比较的空格处理
对于链式比较表达式,PEP8建议在操作符两侧添加空格:
1 | # 正确写法 |
链式比较的优势:不仅符合PEP8规范,还能提高代码可读性。
1 | # 链式比较的可读性优势 |
4. 缩进
缩进在Python中不仅是格式问题,更是语法的核心组成部分。对缩进的规范直接关系到代码的正确性。
Python 是一种基于缩进的语言,这意味着代码块的开始和结束是通过缩进的空格或制表符来确定的。
python 最具特色的就是使用缩进来表示代码块,不需要使用大括号 {} 。
缩进的空格数是可变的,但是同一个代码块的语句必须包含相同的缩进空格数。实例如下:
1 | if True: |
以下代码最后一行语句缩进数的空格数不一致,会导致运行错误:
1 | if True: |
以上程序由于缩进不一致,执行后会出现类似以下错误:
1 | File "test.py", line 6 |
多行语句可以使用反斜杠 \ 来实现。
1 | a = 1 + \ |
在[](列表)、{}(字典 / 集合)、()(元组 / 表达式组)内部支持多行语句,且不需要额外的续行符(如 \),这是 Python 语法的便捷特性。
1 | a = [1, 2, 3, |
4.1 基础缩进规则
4个空格为标准缩进单位
Python 官方 PEP8 明确规定,标准缩进单位为 4 个空格,而非制表符(Tab):
1 | # 正确写法:使用4个空格缩进 |
- 制表符(Tab)的处理
如果必须使用制表符,应确保所有编辑器将 Tab 设置为4个空格宽度,且同一项目内保持一致:
1 | # 配置编辑器将Tab自动转换为4个空格 |
4.2 嵌套代码块的缩进
嵌套代码块是 Python 中最常见的缩进场景,包括条件语句、循环、函数定义等:
1 | # 正确写法:多层嵌套,每层增加4个空格 |
4.3 多行语句的缩进📚
多行语句的缩进是 Python 代码格式化的难点,PEP8 提供了明确的指导:
1 | # 正确写法:括号内换行,保持一致性 |
- 悬挂缩进的最佳实践
悬挂缩进是处理复杂多行表达式的推荐方式,它具有以下优势:
1 | # 垂直对齐式(适用于简单表达式) |
- 悬挂缩进的优势:当变量名长度变化时,无需调整对齐,降低维护成本。例如:
1 | # 长变量名的场景 |
5. 特殊语法结构的缩进 📚
5.1 装饰器
- (Decorator)的缩进
装饰器位于函数或方法定义前,装饰器行与被修饰函数/方法对齐,不额外缩进:
1 | # 正确写法 |
5.2 上下文管理器
- 上下文(With Statement)的缩进
with语句的缩进规则与普通代码块一致,但多层嵌套时需注意对齐:
1 | # 正确写法 |
5.3 异常处理
- (try-except)的缩进
异常处理语句的各分支(try, except, else, finally)应保持同一缩进层级:
1 | # 正确写法 |
5.4 类与方法的缩进
类与方法的缩进层级有明确规范:
1 | # 正确写法 |
5.5 列表推导式和生成器表达式的缩进
列表推导式和生成器表达式在换行时也有特定的缩进规范:
1 | # 正确写法 |
==练习:==
第一部分
下列哪些是合法的 Python 标识符?哪些不合法?请说明原因。
name123abc_scoremy-ageifuser_name1class姓名
简单说明 Python 标识符的命名规则。
下列变量名中,哪些符合Python 命名规范(PEP8)?
UserNameuser_namegetUserInfostudent_score
什么是关键字?关键字能不能当作变量名使用?
简单解释:什么是编码?为什么 Python 中常用 UTF-8 编码?
写出一条在 Python 文件开头声明 UTF-8 编码的注释语句。
第二部分
- 下面代码运行会报错,请指出错误类型并改正:
1 | 1name = "Tom" |
下面变量名哪些语法合法但不推荐使用?为什么?
_private__init__abc123O0O0(字母 O 与数字 0 混合)
思考:
- 标识符区分大小写吗?
Age和age是同一个变量吗? - 中文可以做变量名吗?实际开发中建议使用吗?
- 标识符区分大小写吗?
关于编码:
- 如果一个文件用 GBK 保存,用 UTF-8 打开会出现什么现象?
- 为什么统一使用 UTF-8 可以避免乱码问题?
拓展思考:
为什么 Python 3 默认使用 UTF-8,而 Python 2 经常需要手动声明编码?
参考答案
第一部分
合法与不合法标识符判断
name:合法123abc:不合法,不能以数字开头_score:合法my-age:不合法,不能包含减号-if:不合法,属于 Python 关键字user_name1:合法class:不合法,属于 Python 关键字姓名:合法(Python3 支持中文标识符)
Python 标识符命名规则
- 由**字母、数字、下划线_**组成
- 不能以数字开头
- 严格区分大小写
- 不能是 Python 关键字(if、for、class 等)
- 可以使用中文(不推荐)
符合 PEP8 规范
user_name、student_score符合(蛇形命名法)UserName、getUserInfo不符合(PEP8 推荐小写 + 下划线)
关键字
- 关键字是 Python 语言内部保留的、有特殊语法含义的单词
- 不能作为变量名、函数名等标识符使用
编码与 UTF-8
- 编码:是字符与二进制数据之间的转换规则
- UTF-8 兼容广、支持中文等多国语言,是 Python3 默认编码
UTF-8 声明
1 | # -*- coding: utf-8 -*- |
第二部分
报错原因与改正
错误:变量名
1name以数字开头,语法非法改正:
1 | name = "Tom" |
合法但不推荐的变量名
_private:单下划线开头,约定为内部使用,外部不建议直接用__init__:双下划线开头结尾,是 Python 内置特殊方法,自定义不要乱用O0O0:极易混淆,可读性差,不推荐
大小写与中文变量
- Python 标识符区分大小写,
Age和age是两个不同变量 - 中文可以做变量名,但实际开发不建议,兼容性和可读性差
- Python 标识符区分大小写,
编码乱码问题
- GBK 文件用 UTF-8 打开会出现中文乱码
- UTF-8 是通用标准,统一编码可避免读写时编码不匹配
Python2 与 Python3 编码区别
- Python2 默认 ASCII,不支持中文,必须手动声明编码
- Python3 默认 UTF-8,原生支持中文,基本不用手动声明编码
